
Recent Posts
Tags
- DB
- 난생처음 R코딩&데이터 분석 저서
- 코딩테스트
- 정보처리기사
- 코딩테스트 python
- 부스트코스
- SQL
- [멀티잇]데이터 시각화&분석 취업캠프(Python)
- 기초다지기
- 빅데이터 분석 기반 에너지 운영 관리자 양성 및 취업과정
- AI 플랫폼을 활용한 데이터 분석
- PY4E
- 파이썬
- 빅분기
- 빅데이터분석기사
- Oracle
- boostcourse
- 네이버부스트캠프
- boostcoures
- 이기적
- 이것이 취업을 위한 코딩테스트다 with 파이썬
- 오라클
- 프로그래머스
- 데이터베이스
- 인공지능기초다지기
- r
- Ai
- python
- 데이터 분석 기반 에너지 운영 관리자 양성 및 취업과정
- Machine Learning
- Today
- Total
매일공부
[sklearn] 의사결정트리(Decision Tree) 본문
의사결정트리?
- 질문에 근거하여 규칙을 통해 데이터를 분류, 회귀 분석 지도학습 모델
- 노드들로 이루어진 tree를 생성
- 한 분기마다 변수 영역 2개로 구분

구성
- 노드 node : 질문이나 정답
- 부모노드 Root Node : 가장 처음의 분류 기준
- 자식노드 Intermediate Node : 중간 분류 기준
- 자식노드 Terminal(Leaf) Node : 가장 마지막 노드
불순도 Impurity
- 복잡성
- 제대로 분류되지 않고 섞여 있는 정도
- 낮을수록 good
정보이득 (IG, Information Gain)
- ( 현재 노드의 불순도 )와 ( 자식노드의 불순도 ) 차이
각 노드에서 분기하기 위한 최적 질문
- 순수도 최대
- 자식노드의 불순도 최소
- 정보이득 최대
>> 되도록
불순도 측정
- 지니(Gini) 지수
- 엔트로피(Entropy) 지수
- 분류오류(classification error)
의사결정트리 구성 단계
- Root 노드의 불순도 계산
- 나머지 속성에 대해 분할 후 자식노드의 불순도 계산
- 각 속성에 대한 IG 계산 후, IG가 최대가 되는 분기조건을 찾아 분기
- 모든 leaf 노드의 불순도가 0이 될때까지 2,3을 반복 수행
예제) 링크참고 : https://wooono.tistory.com/104
[ML] 의사결정트리(Decision Tree) 란?
의사결정트리(Decision Tree)란? 의사결정트리는 일련의 분류 규칙을 통해 데이터를 분류, 회귀하는 지도 학습 모델 중 하나이며, 결과 모델이 Tree 구조를 가지고 있기 때문에 Decision Tree라는 이름을
wooono.tistory.com
FullTree > 과적합 문제(Overfittion)
- 모든 leaf노드의 불순도 = 0 / 순수도 = 100인 Tree
- 과적합으로 일반화 시 성능↓
가지치기(Pruning)
- 의사결정트리 모델의 성능 일반화 방법
- 특정 노드 밑의 하부 트리 제거
- 비용함수
: CC(T) = Err(T) + α × L(T)
: 비용 복잡도 = 오분류율 + 가중치 * 중간노드의 수 - 참고 : https://ratsgo.github.io/machine%20learning/2017/03/26/tree/
가치치기 진행 기준
- IG의 값이 일정 수준 이하로 안 내려가도록 제한 (하나의 노드가 분할하기 위한 최소 데이터 수 제한)
- leaf 노드의 최대 개수 제한
- max_depth의 수(깊이)를 제한
의사결정트리 모델의 장점
- 데이터의 전처리(정규화, 결측치, 이상치 등)를 하지 않아도 됨
- 수치형과 범주형 변수를 분석 가능
의사결정트리 모델의 단점(한계)
- 샘플의 사이즈가 크면 효율성 및 가독성 떨어짐
- 과적합 발생 가능성으로 튜닝필요
- Hill Climbing 방식 및 Greedy 방식(한번 분기하면 되돌아갈 수 없음) > 최적 트리 생성 보장x
- 한 번에 하나의 변수만 고려 = 변수간 상호작용 파악 어려움
=>> 한계점 극복으로 나온 모델 : 랜덤 포레스트
의사결정트리 종류
- 분류모델
- 불순도 최소화 = 정보이득 최대화 방향으로 분기
- 분리 기준 : 지니계수 / 엔트로피 계수 / 카이제곱 통계량의 P-value
- 회귀모델
- 분산 최대 감소 방향으로 분기
- 분리 기준 : F 통계량의 P-value / 분산 감소량
의사결정트리 알고리즘
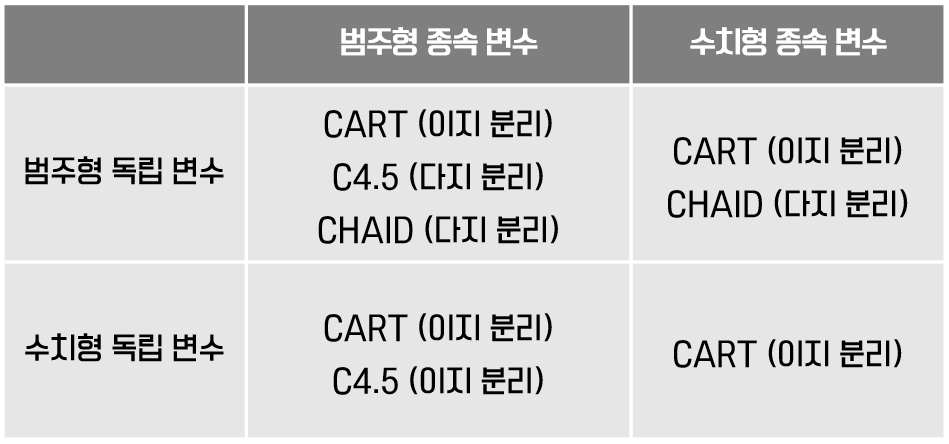
CART(Classification and Regression Trees)
- 분류 모델 : 지니계수를 가장 많이 감소시켜주는 변수
- 회귀 모델 : 노드별로 값의 평균을 구하고, 분산을 가장 많이 감소시켜주는 변수
C4.5
- 분류 모델 : 엔트로피계수를 가장 많이 감소시켜주는 변수
CHAID
- 분류 모델 : 카이제곱 통계량 커서, p-value값이 가장 작은 변수
- 회귀 모델 : 분산 분석표(ANOVA)의 F통계량의 값이 커서, p-value값이 가장 작은 변수
from sklearn.tree import DecisionTreeClassifier의 파라미터 :
- crierion : 정보량 계산 시 사용할 수식 (gini / entropy)
- max_depth : 생성할 트리의 높이
- min_samples_split : 분기를 수행하는 최소한의 데이터 수
- max_leaf_nodes : 리프 노드가 가지고 있을 수 있는 최대 데이터 수
#Decision Tree Classifier 하이퍼파라미터
- criterion: {“gini”, “entropy”}, default=”gini”
- splitter: {“best”, “random”}, default=”best”
- max_depth: int, default=None
- min_samples_split: int or float, default=2
- min_samples_leaf: int or float, default=1
예시코드]
from sklearn.tree import DecisionTreeClassifier
hyperparameters = {
'criterion' : ['gini', 'entropy'],
'splitter' : ['best', 'random'],
'max_depth' : [None, 1, 2, 3, 4, 5],
'min_samples_split' : list(range(2,5)),
'min_samples_leaf' : list(range(1,5))
}
* 내용참고&출처 : 태그의 수업을 복습 목적으로 정리한 내용입니다.
'IT > ML' 카테고리의 다른 글
| [sklearn] SVM(Support Vector Machine) (0) | 2022.11.09 |
|---|---|
| [sklearn] 앙상블학습 > 랜덤 포레스트 (0) | 2022.11.07 |
| [Machine Learning] TensorFlow, Keras (0) | 2022.11.03 |
| [sklearn] 모델 정확도 평가; 오차측정 지표 (0) | 2022.11.03 |
| Machine Learning 수업 전체 흐름 & 키워드 (0) | 2022.11.03 |
'IT/ML' Related Articles
more




Comments