
Recent Posts
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
250x250
Tags
- python
- 빅데이터 분석 기반 에너지 운영 관리자 양성 및 취업과정
- 난생처음 R코딩&데이터 분석 저서
- 코딩테스트
- 이것이 취업을 위한 코딩테스트다 with 파이썬
- 파이썬
- 프로그래머스
- PY4E
- 이기적
- 정보처리기사
- 오라클
- boostcourse
- SQL
- AI 플랫폼을 활용한 데이터 분석
- 데이터베이스
- 기초다지기
- r
- 코딩테스트 python
- [멀티잇]데이터 시각화&분석 취업캠프(Python)
- Ai
- 부스트코스
- 데이터 분석 기반 에너지 운영 관리자 양성 및 취업과정
- 빅분기
- Machine Learning
- 네이버부스트캠프
- 빅데이터분석기사
- DB
- boostcoures
- 인공지능기초다지기
- Oracle
- Today
- Total
매일공부
[AI 기초 다지기] 파이썬 스타일 코드 본문
- Why Pythonic Code?
- 남 코드에 대한 이해도 > 많은 개발자들이 python 스타일로 코딩
- 효율 > 단순 for loop append보다 list가 조금 더 빠름. 익숙해지면 코드도 짧아짐
- split 함수
- string type의 값을 “기준값”으로 나눠서 List 형태로 변환
items = 'zero one two three'.split() # 빈칸을 기준으로 문자열 나누기
print ("items: ", items)
#items: ['zero', 'one', 'two', 'three']
example = 'python, java, javascript' # ","을 기준으로 문자열 나누기
for content in example.split(","):
print (content.strip())
#python
#java
#javascript
example = 'teamlab.technology.io'
subdomain, domain, tld = example.split('.') # "."을 기준으로 문자열 나누기 → Unpacking
print(subdomain, domain, tld)
#teamlab technology io
- join 함수
- String으로 구성된 list를 합쳐 하나의 string으로 반환
>>> colors = ['red', 'blue', 'green', 'yellow']
>>> result = ''.join(colors)
>>> result
'redbluegreenyellow'
>>> result = ' '.join(colors) # 연결 시 빈칸 1칸으로 연결
>>> result
'red blue green yellow'
>>> result = ', '.join(colors) # 연결 시 ", "으로 연결
>>> result
'red, blue, green, yellow'- list comprehension
- 기존 List 사용하여 간단히 다른 List를 만드는 기법
- 포괄적인 List, 포함되는 리스트라는 의미로 사용됨
- 파이썬에서 가장 많이 사용되는 기법 중 하나
- 일반적으로 for + append 보다 속도가 빠름
>> 속도 측정은 %%time 명령어 사용(중간에 넣는 것이 아니라 셀의 가장 처음)
1. 한줄로 표현 가능 > [변수 활용값 for 변수 in 범위]
###General Style###
result = []
for i in range(10):
result.append(i)
print("General Style", result)
#General Style [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
###List Comprehension###
result = [i for i in range(10)]
print("List Comprehension", result)
#List Comprehension [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
2. Nested Loop 중첩 반복문 [변수 활용값 for 변수1 in 범위 for 변수2 in 범위]
import pprint
word_1 = "Hello"
word_2 = "World"
# Nested For loop
pprint.pprint([i+j for i in word_1 for j in word_2] )
# i 고정 > j 하나씩 가져와 결과 생성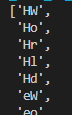
> import pprint : 결과 하나씩 아래로 프린트 됨
> 필요에 따라 이게 훨씬 깔끔할 경우가 있음
- 1줄 < 5줄 : 좀 더 짧게 표현 가능
###General Style###
result = []
for i in word_1: #i가 먼저 고정
for j in word_2: #i 뒤에 j가 바뀜
result.append(i+j)
print(result)
3. Filter
- if문 : [변수 활용값 for 변수 in 범위 if 조건]
>>> result = [i for i in range(10) if i % 2 == 0]
>>> print("List Comprehension_even", result)
List Comprehension_even [0, 2, 4, 6, 8]
- if else문 : [변수 활용값 if 조건 else 아닐 경우의 실행문 for 변수 in 범위]
case_1 = ["A","B","C"]
case_2 = ["D","E","A"]
result = [i+j for i in case_1 for j in case_2]
print("base:", result)
#base: ['AD', 'AE', 'AA', 'BD', 'BE', 'BA', 'CD', 'CE', 'CA']
result = [i+j if not(i==j) else i for i in case_1 for j in case_2]
# Filter: i랑 j과 같다면 i 추가
print("if not:", result)
#if not: ['AD', 'AE', 'A', 'BD', 'BE', 'BA', 'CD', 'CE', 'CA']
result.sort()
print("sort:", result)
#sort: ['A', 'AD', 'AE', 'BA', 'BD', 'BE', 'CA', 'CD', 'CE']
4. Two dimentional list 이차원 리스트
- [[변수 활용값들] for 변수 in 범위]
import pprint
words = 'The quick brown fox jumps over the lazy dog'.split() #문장을 빈칸 기준으로 나눠 list로 변환
print (words)
#['The', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog']
stuff = [[w.upper(), w.lower(), len(w)] for w in words]
# list의 각 elemente들을 대문자, 소문자, 길이로 변환하여 two dimensional list로 변환
pprint.pprint(stuff)
#[['THE', 'the', 3],
# ['QUICK', 'quick', 5],
# ['BROWN', 'brown', 5],
# ['FOX', 'fox', 3],
# ['JUMPS', 'jumps', 5],
# ['OVER', 'over', 4],
# ['THE', 'the', 3],
# ['LAZY', 'lazy', 4],
# ['DOG', 'dog', 3]]
- [[변수 활용값 for 변수1 in 범위] for 변수2 in 범위]
case_1 = ["A","B","C"]
case_2 = ["D","E","A"]
#one : i고정 > j변화
result = [i+j for i in case_1 for j in case_2]
print(result)
#['AD', 'AE', 'AA', 'BD', 'BE', 'BA', 'CD', 'CE', 'CA']
#two : j고정 > i변화
result = [ [i+j for i in case_1] for j in case_2]
print(result)
#[['AD', 'BD', 'CD'], ['AE', 'BE', 'CE'], ['AA', 'BA', 'CA']]<다양한 방식의 리스트값 출력>
- enumerate
- list의 element를 추출할 때 인덱스(번호)를 붙여서 추출
mylist = ['a', 'b', 'c', 'd']
mylist_enumerate = list(enumerate(mylist)) # list의 있는 index와 값을 unpacking하여 list로 저장
print(mylist_enumerate)
#[(0, 'a'), (1, 'b'), (2, 'c'), (3, 'd')]
text = '''Artificial intelligence (AI),
is intelligence demonstrated by machines,
unlike the natural intelligence displayed by humans and animals.'''
text_dict = {i:j for i,j in enumerate(text.split())}
# 문장을 list로 만들고 list의 index와 값을 unpacking하여 dict로 저장
print(text_dict)
#{0: 'Artificial', 1: 'intelligence', 2: '(AI),', 3: 'is', 4: 'intelligence', 5: 'demonstrated', 6: 'by', 7: 'machines,', 8: 'unlike', 9: 'the', 10: 'natural', 11: 'intelligence', 12: 'displayed', 13: 'by', 14: 'humans', 15: 'and', 16: 'animals.'}
- zip
- 두 개의 list의 값을 병렬적으로 추출함
alist = ['a1', 'a2', 'a3']
blist = ['b1', 'b2', 'b3']
print([[a, b] for a, b in zip(alist, blist)]) #병렬적으로 값 추출
#[['a1', 'b1'], ['a2', 'b2'], ['a3', 'b3']]
print([c for c in zip(alist, blist)]) #묶으면 tuple로 반환
#[('a1', 'b1'), ('a2', 'b2'), ('a3', 'b3')]
math = (100, 90, 80)
kor = (90, 90, 70)
eng = (90, 80, 70)
print([sum(value) / 3 for value in zip(math, kor, eng)])
#zip으로 점수를 먼저 묶어줌 > 세 학생의 평균점수를 뽑을 수 있음
#[93.33333333333333, 86.66666666666667, 73.33333333333333]
- 만약 리스트값이 서로 동일하지 않다면?
alist = ['a1', 'a2', 'a3']
blist = ['b1', 'b2']
for a,b in zip(alist, blist): print(a, b)
#a1 b1
#a2 b2
#>> 쌍만 출력되고 나머지 생략됨
- enumerate & zip
- zip으로 병렬 > 번호 붙여서 추출
>>> alist = ['a1', 'a2', 'a3']
>>> blist = ['b1', 'b2', 'b3']
>>> for i, values in enumerate(zip(alist, blist)):
... print(i, values) #zip으로 묶고 enumerate로 같은 인덱스끼리 묶음
...
#index alist[index] blist[index] 표시
0 ('a1', 'b1')
1 ('a2', 'b2')
2 ('a3', 'b3')
- lambda & map & reduce
- 간단한 코드로 다양한 기능을 제공
- 코드의 직관성이 떨어져서 lambda나 reduce는 python3에서 사용을 권장하지 않음
- Legacy library나 다양한 머신러닝 코드에서 여전히 사용중
1. 람다 lambda
- 수학의 람다 대수에서 유래함
- 함수 이름 없이, 함수처럼 쓸 수 있는 익명함수
- 별도의 def나 return 작성x > 함수 선언x
## General function ##
def f(x, y):
return x + y
print(f(1,4)) #5
## Lambda function ##
f = lambda x, y: x + y
print(f(4, 5)) #9
print((lambda x, y: x + y)(4, 5))
#변수에 굳이 할당 안 해도 알아서 들어감
#일회성으로 다른 함수에 전달하는 용도로 많이 사용됨
up_low = lambda x : "-".join(x.split())
up_low("My Happy") #'My-Happy'
up_low = lambda x : x.upper() + x.lower()
up_low("My Happy") #'MY HAPPYmy happy'
2. map 함수 (고차함수)
- 고차함수 - 하나 이상의 함수를 인수로 받는 함수로 map도 고차함수
- 연속 데이터를 저장하는 시퀀스형에서 요소마다 같은 기능을 적용할 때 사용
- raw data를 새로운 구조로 만듦
- 두 개 이상의 list에도 적용 가능함, if filter도 사용가능
- python3는 제너레이터(generator) 개념이 강화 > list을 붙여줘야 list 사용가능
- 제너레이터 : 시퀀스형 자료형의 데이터를 처리할 때, 실행시점의 값을 생성, 메모리 효율적
def f(x):
return x + 5
ex = [1, 2, 3, 4, 5]
list(map(f, ex)) #이것보다는
#이렇게 사용하는 것을 권장
[f(value) for value in ex]
#출력: [6, 7, 8, 9, 10]
## if filter ##
ex = [1,2,3,4,5]
f = lambda x, y: x + y
print(list(map(f, ex, ex))) #[2, 4, 6, 8, 10]
## parameter가 2개인 lambda에서도 2개의 값을 넣어주고 zip처럼 병렬로 반환 가능
list(map(lambda x: x ** 2 if x % 2 == 0 else x, ex)) #이것보다는
#이렇게 사용하는 것을 권장
[value**2 if value % 2 ==0 else value for value in ex]
#출력 [1, 4, 3, 16, 5]
3. reduce function
- map function과 달리 list에 똑같은 함수를 적용해서 통합
- 대용량 데이터를 다룰 때 주로 사용
from functools import reduce
print(reduce(lambda x, y: x+y, [1, 2, 3, 4, 5]))
#15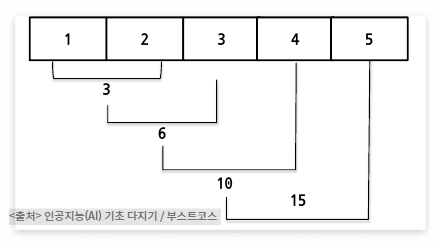
- iterable objects
- Sequence형 자료형에서 데이터를 순서대로 추출하는 object
- 내부적 구현으로 __iter__ 와 __next__ 가 사용됨
- iter() 와 next() 함수로 iterable 객체를 iterator object로 사용
cities = ["Seoul", "Busan", "Jeju"]
memory_address_cities = iter(cities)
print(next(memory_address_cities))
print(next(memory_address_cities))
print(next(memory_address_cities))
next(memory_address_cities)
#Seoul
#Busan
#Jeju
#Traceback (most recent call last): StopIteration
- generator
- iterable object를 특수한 형태로 사용해주는 함수
- element가 사용되는 시점에 값을 메모리에 반환
: yield를 사용해 한번에 하나의 element만 반환함 - list comprehension과 유사한 형태로 generator형태의 list 생성
> 생성만 하고 실제로 값을 넣어두진 않음 - generator expression 이라는 이름으로도 부름
- [ ] 대신 ( ) 를 사용하여 표현
- Why generator?
- 일반적인 iterator는 generator에 반해 훨씬 큰 메모리 용량 사용
- When generator?
- list 타입의 데이터를 반환해주는 함수 만들 때
: 읽기 쉬운 장점, 중간 과정에서 loop가 중단될 수 있을 때 - 큰 데이터 처리할 때 : 데이터가 커도 처리의 어려움이 없음
- 파일 데이터 처리할 때
- list 타입의 데이터를 반환해주는 함수 만들 때
## General function ##
def general_list(value):
result = []
for i in range(value):
result.append(i)
return result
print(general_list(50))
from sys import getsizeof
result = general_list(500)
print(type(result)) #<class 'list'>
print(sys.getsizeof(result)) #4216
## generator ##
def geneartor_list(value):
result = []
for i in range(value):
yield i #주소값만 가지고 있음
for a in geneartor_list(50) :
print(a) #호출하고 나서야 값을 반환
gen_ex = (n*n for n in range(500))
print(type(gen_ex)) #<class 'generator'>
print(getsizeof(gen_ex)) #112
- function passing arguments
- 키워드 인수 Keyword arguments
- 함수에 입력되는 parameter의 변수명을 사용, arguments를 넘김
def print_somthing(my_name, your_name):
print("Hello {0}, My name is {1}".format(your_name, my_name))
print_somthing("Sungchul", "TEAMLAB")
print_somthing(your_name="TEAMLAB", my_name="Sungchul")
#둘다 Hello TEAMLAB, My name is Sungchul
- 디폴트 인수 Default arguments
- parameter의 기본 값을 사용, 입력하지 않을 경우 기본값 출력
def print_somthing_2(my_name, your_name="TEAMLAB"):
print("Hello {0}, My name is {1}".format(your_name, my_name))
print_somthing_2("Sungchul", "TEAMLAB")
print_somthing_2("Sungchul")
#둘다 Hello TEAMLAB, My name is Sungchul
- Variable-length arguments 가변인자, 가변길이
- 개수가 정해지지 않은 변수를 함수의 parameter로 사용하는 법
- Keyword arguments와 함께, argument 추가 가능
- Asterisk(*) 기호를 사용하여 함수의 parameter를 표시함
- 입력된 값은 tuple type으로 사용할 수 있음
- 가변인자는 오직 한 개만 맨 마지막 parameter 위치에 사용가능
- 가변인자는 일반적으로 *args를 변수명으로 사용
- 기존 parameter 이후에 나오는 값을 tuple로 저장함
def asterisk_test(a, b, *args):
return a+b+sum(args)
print(asterisk_test(1, 2, 3, 4, 5)) #*args = 3, 4, 5
#15
def asterisk_test_2(*args):
x, y, z = args
return x, y, z
print(asterisk_test_2(3, 4, 5)) #듀플로 저장됨
#(3, 4, 5)
- 키워드 가변인자 (Keyword variable-length )
- Parameter 이름을 따로 지정하지 않고 입력하는 방법
- asterisk(*) 두개를 사용하여 함수의 parameter를 표시함
- 입력된 값은 dict type으로 사용할 수 있음
- 가변인자는 오직 한 개만 기존 가변인자 다음에 사용
> 함수명(일반인수, *가변인수, **키원드 가변인수) 순서 필수
def kwargs_test_3(one,two, *args, **kwargs):
print(one+two+sum(args))
print(args)
print(kwargs)
kwargs_test_3(3,4,5,6,7,8,9, first=3, second=4, third=5)
#42
#(5, 6, 7, 8, 9) 가변인자는 안 들어가도 상관없음
#{'first': 3, 'second': 4, 'third': 5}
- asterisk
- 흔히 알고 있는 * 를 의미함
- 단순 곱셈, 제곱연산, 가변 인자 활용 등 다양하게 사용됨
## *args ##
def asterisk_test(a, *args):
print(a, args)
print(type(args))
asterisk_test(1,2,3,4,5,6)
#1 (2, 3, 4, 5, 6)
#<class 'tuple'>
## **kargs ##
def asterisk_test(a, **kargs):
print(a, kargs)
print(type(kargs))
asterisk_test(1, b=2, c=3, d=4, e=5, f=6)
#1 {'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 6}
#<class 'dict'>
- asterisk – unpacking a container
- tuple, dict 등 자료형에 들어가 있는 값을 unpacking
- 함수의 입력값, zip 등에 유용하게 사용가능
def asterisk_test(a, **kargs):
print(a, kargs) #1 {'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 6}
print(type(kargs)) #<class 'dict'>
asterisk_test(1, b=2, c=3, d=4, e=5, f=6)
def asterisk_test(a, *args):
print(a, args)
print(type(args)) #<class 'tuple'>
asterisk_test(1, *(2,3,4,5,6)) #5개의 변수로 들어가서 다시 튜플로 묶임
#1 (2, 3, 4, 5, 6)
def asterisk_test(a, args):
print(a, *args)
asterisk_test(1, (2,3,4,5,6)) #튜플로 1개만 들어감
#1 2 3 4 5 6
for data in zip(*[[1,2], [3,4], [5,6]]): #이차원리스트 > [1, 2], [3, 4], [5, 6]으로 언패킹
print(data)
print(type(data))
#(1, 3, 5) : zip()이 튜플로 묶어줌
#<class 'tuple'>
#(2, 4, 6)
#<class 'tuple'>
def asterisk_test(a, b, c, d):
print(a, b, c, d)
data = {"b":1, "c":2, "d":3}
asterisk_test(10,**data) #**이 딕셔너리형을 언패킹해줌
#10 1 2 3
728x90
'Programming > Python' 카테고리의 다른 글
| [AI 기초 다지기] 파이썬 Module and Project (0) | 2022.08.02 |
|---|---|
| [AI 기초 다지기] 파이썬 class와 instance (0) | 2022.08.01 |
| [AI 기초 다지기] 파이썬 데이터 구조, 자료구조 (0) | 2022.07.30 |
| [AI 기초 다지기] 파이썬 - 함수 개발 가이드라인 (0) | 2022.07.29 |
| [AI 기초 다지기] 파이썬 advanced function (0) | 2022.07.29 |
'Programming/Python' Related Articles
more



Comments