[SQL 입문] 데이터 결합; 그룹함수의 subquery
SELECT ~문 = query문
SUBQUERY(nested query, inner query)
- 하나의 SQL문 안에 포함되는 또다른 SQL문
- 조건값을 몰라서 query를 2번 이상 수행해야하는 경우, 먼저 수행해야 하는 query를 subquery로 선언
SELECT ~ --main query, outer query
FROM
WHERE 컬럼 연산자 ( SELET ~ -- subquery, nested query, inner query
FROM ~ -- 먼저 1번 수행
[WHERE~ ]
[group by ~]
[having~] ) ; --order by절을 제외하고 모든 구문 정의 할 수 있음)- 서브쿼리 사용 가능 위치
: select절, from절, where절, having절, order by절
: decode안 > INSERT의 values절, INSERT into절, UPDATA의 where절, UPDATA set절, DELETE의 where절
- subquery의 종류
- single row subquery
- subquery의 결과 레코드 = 1개
- scalar subquery = 결과가 단일값(1개의 레코드에서 1개의 컬럼)
- single row operator와 함께 사용(>, >=, =, <=, <>)
- multiple row subquery
- subquery의 결과 레코드가 n개
- multiple column subquery
- multiple row operator와 함께 사용(any, all, in)
- inline view
- select의 from절의 subquery
- SQL문이 실행될 때만 임시적으로 메모리에 생성되는 논리적 테이블 (동적인 뷰)
= 실행시점에 생성되는 논리적인 view
> 데이터베이스에 해당 정보 저장X - 일반적인 뷰 = 정적 뷰(Static View)
- 인라인 뷰 = 동적 뷰(Dynamic View)
- corelated subquery
- 상관관계
- 서브쿼리를 시행하기 위해 메인쿼리로부터 레코드를 가져와서(참조해서) 수행하는 쿼리,
- main query의 후보행수만큼 subquery가 반복적으로 수행됨
> 성능문제, join이 더 유리한 경우도 있음 - exists 연산자와 함께 사용
> 메인 쿼리에서 서브쿼리로 컬럼값을 전달
> 서브쿼리에서 전달받은 컬럼값을 가지는 레코드가 존재하는지 검사
> 존재하면 그걸 가지고 나머지는 검사 안함. - corelated subquery만 사용 양식이 다름
SELECT column1, column2, ...
FROM table main #후보행 → ↓
WHERE 컬럼연산자 column1 operator (SELECT colum1
FROM table2 sub
WHERE sub1.expression1 = main.expression1)1. 후보 행을 가져온다(메인쿼리에서 인출한다)
2. 후보 행의 값을 사용하여 서브쿼리를 실행한다
3. 서브쿼리 결과값을 사용하여 메인 쿼리의 후보 행의 조건을 확인한다
(조건을 만족하면 결과집합으로 생성 > 만족하지 않으면 결과집합 x )
4. 메인 쿼리의 후보 행이 남지 않을 때까지 반복한다
※ 실행계획을 확인하면, join이 더 유리할수도 있음 (실행 성능 차이) > 확인 후 유리한 성능으로 작성 및 실행
- top-n쿼리
SELECT rownum , col1, col2, col3
FROM (SELECT col1, col2, col3
FROM ~
ORDER BY~)
WHERE rownum < n;
- 12c버전 부터 > from 절의 subquery에서만 order by절을 쓸 수 있음
SELECT
FROM
[WHERE~ ]
[group by ~]
[having]
[order by]
[offset n rows]
[fetch next 정수n rows only | fetch next 정수n rows with ties | fetch first 정수n percent rows only ];- OFFSET n rows = n(정수)개의 행을 건너뜀
- FETCH NEXT n rows only = n개의 행만 가져옴
- FETCH NEXT n rows with ties = 전부 가져옴
- FETCH first n percent rows only = 지정해서 가져옴
※주의할 점 : 메인쿼리의 결과가 null인 경우 > 서브쿼리의 결과집합에 null이 포함되어 있는지 확인해야함
-- 조건값을 몰라서 query를 2번 이상 수행해야하는 경우,
먼저 수행해야 하는 query를 subquery로 선언
= subquery의 결과를 받아서 수행해야 하는 query를 main query로 선언
Q. 7566번 사원보다 급여를 많이 받는 사원의 이름, 급여를 조회하라
SELECT ename, sal
FROM emp
WHERE sal > (SELECT sal
FROM emp
WHERE empno = '7566'); --7566번은 사번!!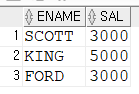
--where절에 조건 각각 subquery 선언 가능
Q. emp타이블에서 7521번 사원과 업무가 같고 급여가 7934번 사원보다 많은 사원의 사원번호, 이름, 담당업무, 입사일자, 급여를 조회하라
SELECT empno, ename, job, hiredate, sal
FROM emp
WHERE sal > (SELECT sal
FROM emp
WHERE empno = '7934')
and job = (SELECT job
FROM emp
WHERE empno = '7521');
--subquery에 그룹함수 사용 가능
Q. emp 테이블에서 급여를 제일 많이 받는 사원의 이름, 부서번호, 급여, 입사일을 조회하라
SELECT ename, deptno, sal, hiredate
FROM emp
WHERE sal = (SELECT max(sal) FROM emp);
Q. emp 테이블에서 급여의 평균보다 적은 급여를 받는 사원의 사원번호, 이름, 담당업무, 급여, 부서번호를 출력
SELECT empno, ename, job, sal, deptno
FROM emp
WHERE sal < (SELECT avg(sal) FROM emp);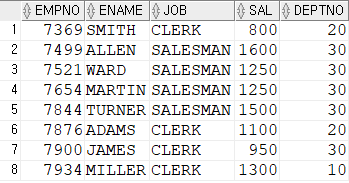
Q. emp 테이블에서 부서별 최소급여가 20번 부서의 최소 급여보다 높은 부서를 조회하라(부서번호와 최소급여)
SELECT deptno, min(sal)
FROM emp
GROUP BY deptno
HAVING min(sal) > (SELECT min(sal)
FROM emp
WHERE deptno = '20');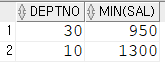
--multiple row subquery / pair-wise VS non-pair-wise 비교(쌍으로 함께 비교)
Q. 각 부서별 최고 급여를 받는 사원의 사원번호, 이름, 급여, 부서번호를 조회
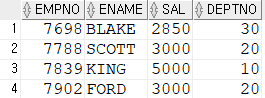
SELECT empno, ename, sal, deptno
FROM emp
where sal in (SELECT max(sal) --multiple row subquery
FROM emp
GROUP BY deptno);# 잘 나온 것 같지만?
update emp set deptno=10, sal=3000
where empno = 7000;
commit;
# 비어있는 홍길동사원의 급여를 업데이트해서 다시 본다면? >> 잘못 나옴
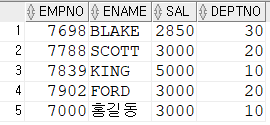
>> 부서와 최고 급여를 "쌍으로" 비교해야함 >> multiple column subquery
SELECT empno, ename, sal, deptno
FROM emp
where (deptno, sal) in (SELECT deptno, max(sal) --pair-wise 비교
FROM emp
GROUP BY deptno);
SELECT empno, ename, sal, deptno
FROM emp
where deptno in (SELECT deptno
FROM emp
GROUP BY deptno)
and sal in (SELECT max(sal)
FROM emp
GROUP BY deptno); --non-pair-wise 비교
--ANY : OR과 같은 의미로 사용 가능
Q. 직무가 SALESMAN이 아닌 사원 중에서 업무가 SALESMAN인 최소 한 명 이상의 사원보다 급여를 많이 받는 사원의 이름, 급여, 업무를 조회
SELECT ename, sal, job
FROM emp
where job != 'SALESMAN'
AND sal >ANY (SELECT sal FROM emp
WHERE job = 'SALESMAN');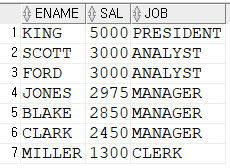
--ALL : max와 같은 의미로 사용 가능
Q. 직무가 SALESMAN이 아닌 사원 중에서 업무가 SALESMAN인 모든 사원의 급여보다 급여를 많이 받는 사원의 이름, 급여, 업무를 조회
SELECT ename, sal, job
FROM emp
where job != 'SALESMAN'
AND sal >ALL (SELECT sal FROM emp
WHERE job = 'SALESMAN');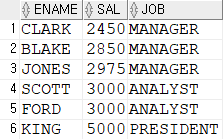
conn c##hr/oracle
select last_name "Name", length(last_name) "Length"
from employees
where last_name like '&lname%';
--&변수명은 치환변수로서 실행시에 값 입력을 요청함
--pair-wise / non-pair-wise
Q. FORD 또는 BLALK 사원과 관리자 및 부서가 동일한 사원의 정보 조회(단, FORD, BLALK 사원정보는 결과에서 제외)
SELECT *
FROM emp
where (mgr, deptno) in
(SELECT mgr, deptno
FROM emp
WHERE ename in ('FORD', 'BLAKE'))
AND ename NOT IN ('FORD', 'BLAKE'); --pair wise
SELECT *
FROM emp
where mgr in (SELECT mgr
FROM emp
WHERE ename in ('FORD', 'BLAKE'))
AND deptno IN (SELECT deptno
FROM emp
WHERE ename in ('FORD', 'BLAKE'))
AND ename NOT IN ('FORD', 'BLAKE'); --NON-pair wise
- Co-related subquery : 상관관계 서브쿼리
-- inline view
Q. 소속 부서의 평균 급여보다 많은 급여를 받은 사원의 이름, 급여, 부서번호, 입사일, 업무 정보를 검색하라(Co-related subquery와 join)
-- hint : 후보행의 부서번호를 조건으로 서브쿼리에는 부서의 평균 급여 리턴
SELECT ename, sal, deptno, hiredate, job
FROM emp e
WHERE sal > (SELECT avg(sal) FROM emp --Co-related subquery
WHERE deptno = e.deptno); --자기가 속한 부서, 없으면 전체 부서를 대상
SELECT e.ename, e.sal, e.deptno, e.hiredate, e.job
FROM emp e, (SELECT deptno, avg(sal) avg_sal
FROM emp
GROUP BY deptno) e2 --from 절의 subquery는 inline view
WHERE e.sal > e2.avg_sal
and e.deptno = e2.deptno; --join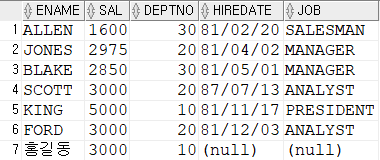
conn c##scott/oracle
Q. job_history, employees로부터 사원들중에서 부서 또는 직무를 2회이상 변경한 사원 조회(사원번호, 현재 직무, 현재 부서번호)
select employee_id, last_name, job_id, department_id
from employees t1
where 2<= (select count(*)
from job_history
where t1.ememployee_id = employee_id)
select employee_id, last_name, job_id, department_id
from employees t1 , (select employee_id, count(*) cnt
from job_history
group by employee_id ) t2
where t1.ememployee_id = t2.employee_id
and t2.cnt >=2 ;
conn c##hr/oracle
Q. 전체 사원들의 급여를 내림차순으로 정렬하고 급여가 높은 사원 5명만 출력
-- hint : from절에 정렬된 데이터 소스 집합 (inline view), rownum
SELECT rownum, empno, ename, deptno, sal --2
FROM emp --1
ORDER BY sal desc; --를 넣으면 순서가 달라짐 --3
SELECT rownum no, empno, ename, deptno, sal
FROM (SELECT empno, ename, deptno, sal
FROM emp
ORDER BY sal desc)
WHERE rownum < 6; --Ton_N쿼리 예전엔 이렇게 사용함
--from 절의 subquery에서만 order by절을 쓸 수 있음
conn c##scott/oracle
SELECT last_name,salary
FROM employees
ORDER BY salary desc
OFFSET 10 rows --10rows를 skip
fetch next 10 rows only; --11번째 행부터 ~20번째행까지 가져옴
conn c##hr/oracle
SELECT ename,sal
FROM emp
ORDER BY sal desc
fetch next 2 rows only; -- 1번째 행부터 ~2번째행까지 가져옴
SELECT ename,sal
FROM emp
ORDER BY sal desc
fetch next 2 rows with ties; --마지막행과 동일한 레코드를 추가로 결과집합에 포함
SELECT last_name, salary
FROM employees
ORDER BY salary desc
fetch first 10 percent rows only;
-- 스칼라 서브쿼리만 올수 있음
-- Scalar subquery : 하나의 행에서 하나의 열 값만 반환
decode 또는 case의 조건, 표현식
select절
insert의 values 절
update문의 set절
Q. 사원번호와 이름, 사원의 부서 위치가 DALLAS이면 TOP 출력하고 부서 위치가 DALLAS가 아니면 BRENCH로 출력하시오
SELECT ename, empno,
CASE WHEN deptno = (SELECT deptno FROM dept
WHERE loc = 'DALLAS') then 'TOP'
else 'BRENCH' end as location
FROM emp;
select ename, empno, decode (deptno , (select deptno from dept
where loc = 'DALLAS'),
'TOP', 'BRENCH') as location
from emp;
Q. 사원이름, 부서번호, 급여, 소속부서의 평균연봉을 함께 출력
SELECT ename, ename, sal,
(SELECT avg(sal) FROM emp
WHERE deptno = e.deptno) as avgsal
FROM emp e; --select절에 Co-related subquery, scalar subquery
Q. 사원이름, 부서번호, 급여, 소속부서를 부서이름으로 오름차순 정렬
SELECT ename, deptno, sal
FROM emp e
ORDER BY (SELECT dname
FROM DEPT
WHERE deptno = e.deptno) desc;
--부서이름도 같이 출력한다면 이렇게
SELECT ename, deptno, sal, (SELECT dname
FROM DEPT
WHERE deptno = e.deptno) dname
FROM emp e
ORDER BY (SELECT dname
FROM DEPT
WHERE deptno = e.deptno) desc;
-- Co-related subquery에서 사용되는 연산자 : exists
conn c##scott/oracle
Q. 사원이 존재하는 부서의 부서번호, 부서명 조회
SELECT department_id, department_name
FROM departments a
WHERE exists (SELECT 'x'
FROM employees
WHERE a.department_id = department_id);
-- 사원 존재유무만 체크 > 처음에 존재하면 나머지 레코드는 검사 안함.
SELECT department_id, department_name
FROM departments a
WHERE not exists (SELECT 1 --여기는 이걸 반환하는 게 아니라서 임의로 아무거나 넣으면 됨
FROM employees
WHERE a.department_id = department_id); -- 사원 존재안하는 부서
Q. emp테이블에서 관리자인 사원들만 조회
SELECT empno, ename
FROM emp
WHERE empno in (SELECT mgr
FROM emp);
--> empno = 7902 or empno = 7698 or 7839, 7566, 7788, 7782, null 전체 or
SELECT empno, ename
FROM emp a
WHERE exists (SELECT 1
FROM emp
WHERE a.empno = mgr);
Q. emp테이블에서 관리자가 아닌 일반(평) 사원들만 조회
SELECT empno, ename
FROM emp a
WHERE not exists (SELECT 1
FROM emp
WHERE a.empno = mgr);
SELECT empno, ename
FROM emp
WHERE empno not in (SELECT mgr
FROM emp); --왜 안나오는건가
-- > empno <> 7902 and empno <> 7698 and 7839, 7566, 7788, 7782, null 전체-- subquery의 결과집합에 null 포함
-- not in 연산자는 null에 대해 null 리턴 > 즉, null 비교 못함
-- subquery의 결과집합에 null이 포함여부를 확인하고 연산자가 null을 비교 못하면
-- 조건 추가하거나 다른 연산자를 사용해야함.
select empno, ename
from emp
where empno not in (select mgr
from emp
where mgr is not null);
select empno, ename
from emp a
where not EXISTS (SELECT 1
FROM emp
where a.empno = mgr);
select employee_id, last_name, salary
from employees
where salary > (select avg(salary)
from employees)
order by 3 ;
* 내용참고&출처 : 태그에서 수강한 수업을 복습 목적으로 정리한 내용입니다.